Llama Recipes使用教程
1. 代码结构概要
(llama_env) [10:55:18] [~/tools/llama-recipes] git(main) 🔥 ❱❱❱ tree -L 1
.
├── CODE_OF_CONDUCT.md
├── configs # 包含 PEFT 方法、FSDP、数据集的配置文件。
├── CONTRIBUTING.md
├── docs # 单 GPU 和多 GPU 微调配方的示例配方。
├── ft_datasets # 包含每个数据集下载和处理的单独脚本。
├── inference # 包括微调模型的推理示例以及如何安全使用它们。
├── LICENSE
├── llama_finetuning.py
├── model_checkpointing # 包含 FSDP 检查点处理程序。
├── multi_node.slurm
├── policies # 包含 FSDP 脚本以提供不同的策略,例如混合精度、变压器包装策略和激活检查点以及任何精度优化器(用于以纯 bf16 模式运行 FSDP)。
├── quickstart.ipynb
├── README.md
├── requirements.txt
├── scripts
├── USE_POLICY.md
└── utils
├── config_utils.py # 覆盖从 CLI 接收到的配置。
├── dataset_utils.py # 获取预处理的数据集。
├── fsdp_utils.py # PEFT 方法提供 FSDP 包装策略。
├── memory_utils.py # 上下文管理器用于跟踪火车循环中的不同内存统计信息。
└── train_utils.py # 提供训练/评估循环和更多训练实用程序。
2. 如何执行微调
(1) 启动代码运行环境依赖
(1.1) SSH命令行服务器10.102.53.103上
# 进入代码根目录
cd /home/dell/tools/llama-recipes
# 激活虚拟环境
source llama_env/bin/activate
此时命令行应该会显示如下结果:
[11:05:48] [~/tools/llama-recipes] git(main) 🔥 ❱❱❱ source llama_env/bin/activate
[11:05:48] [cost 0.099s] source llama_env/bin/activate
(llama_env) [11:05:52] [~/tools/llama-recipes] git(main) 🔥 ❱❱❱
命令行最前面出现(llama_env)这样的字样,表示已经进入了虚拟环境。
(1.2) HPC网页端服务器http://10.102.53.100/上
登陆网页服务器端,选择 ID:725 名称:llama 作业,新建bash窗口。
WARNING: Error loading config file: /home/hengd/.docker/config.json: stat /home/hengd/.docker/config.json: permission deniedroot@8eb57f0a7435:/workspace#
进入代码目录
cd /home/hengd/container/our-tiny-tools/llama-recipes/
激活虚拟环境
source activate /opt/conda/envs/llama/
同样此时命令行最全端会出现(llama)字样。
root@8eb57f0a7435:/home/hengd/container/our-tiny-tools/llama-recipes# source activate /opt/conda/envs/llama/
(llama) root@8eb57f0a7435:/home/hengd/container/our-tiny-tools/llama-recipes#
(2) 添加自定义数据集
本部分以dolly数据集为例讲解如何添加自定义数据集。一般而言包括以下几个步骤:
-
- 数据整理
-
- 代码配置修改
(2.1) 数据整理
nvidia-smi 100第一步: 从数据集网址下载原始数据集databricks-dolly-15k.jsonl文件。

该文件的数据格式为jsonl,每一行为一个四字段(instruction, context, response, category)的字典:
{"instruction": "When did Virgin Australia start operating?", "context": "Virgin Australia, the trading name of Virgin Australia Airlines Pty Ltd, is an Australian-based airline. It is the largest airline by fleet size to use the Virgin brand. It commenced services on 31 August 2000 as Virgin Blue, with two aircraft on a single route. It suddenly found itself as a major airline in Australia's domestic market after the collapse of Ansett Australia in September 2001. The airline has since grown to directly serve 32 cities in Australia, from hubs in Brisbane, Melbourne and Sydney.", "response": "Virgin Australia commenced services on 31 August 2000 as Virgin Blue, with two aircraft on a single route.", "category": "closed_qa"}
第二步: 将数据整理成如下格式json格式, 最外层是列表,列表中每个元素是1个三字段(context, instruction, response)的字段。
[
{
"context": "Virgin Australia, the trading name of Virgin Australia Airlines Pty Ltd, is an Australian-based airline. It is the largest airline by fleet size to use the Virgin brand. It commenced services on 31 August 2000 as Virgin Blue, with two aircraft on a single route.[3] It suddenly found itself as a major airline in Australia's domestic market after the collapse of Ansett Australia in September 2001. The airline has since grown to directly serve 32 cities in Australia, from hubs in Brisbane, Melbourne and Sydney.[4]",
"instruction": "When did Virgin Australia start operating?",
"response": "Virgin Australia commenced services on 31 August 2000 as Virgin Blue, with two aircraft on a single route."
},
{
"context": "",
"instruction": "Which is a species of fish? Tope or Rope",
"response": "Tope"
},
...
]
instruction字段中一般包含提问,即我们希望语言模型回答的内容。context字段中一般包含回答问题所需的依据文本,它属于可选项,可有可没有,视具体任务而定。response字段中包含答案,即我们希望语言模型给出的标准答案内容。
数据格式转化可以编写python程序执行,例如dolly数据转化代码如下:
# (1) 创建列表存放json数据
json_data = []
# (2) 读取jsonl文件的每一行
import jsonlines
with jsonlines.open('databricks-dolly-15k.jsonl') as f:
for d in f: # d 就是每一行的字典
# 将字典中category字段删掉
del d['category']
# 把数据放入json_data列表
json_data.append(d)
# (3) 把json数据保存下来
import json
with open('dolly_data.json', 'w') as f:
json.dump(json_data, f, indent=4)
注意不论你的原始数据集格式如何,你都可以将它转化成llama-recipes可处理的json格式。主要的代码逻辑是:(1) 创建列表 (2) 为列表添加元素,每个元素是一个3字段字典 (3) 保存列表到json文件中
(2.2) 代码配置修改
第一步: 把dolly_data.json文件放入ft_datasets文件夹。
第二步: 在configs/datasets.py文件中添加dolly_dataset类:
# Copyright (c) Meta Platforms, Inc. and affiliates.
# This software may be used and distributed according to the terms of the Llama 2 Community License Agreement.
from dataclasses import dataclass
@dataclass
class samsum_dataset:
dataset: str = "samsum_dataset"
train_split: str = "train"
test_split: str = "validation"
input_length: int = 2048
@dataclass
class grammar_dataset:
dataset: str = "grammar_dataset"
train_split: str = "ft_datasets/grammar_dataset/gtrain_10k.csv"
test_split: str = "ft_datasets/grammar_dataset/grammar_validation.csv"
input_length: int = 2048
@dataclass
class alpaca_dataset:
dataset: str = "alpaca_dataset"
train_split: str = "train"
test_split: str = "val"
data_path: str = "ft_datasets/alpaca_data.json"
##### 以下部分是我们添加的
## dolly_dataset 是数据集名字
## ft_datasets/dolly_data.json 是数据集文件对应的路径
@dataclass
class dolly_dataset:
dataset: str = "dolly_dataset"
train_split: str = "train"
test_split: str = "val"
data_path: str = "ft_datasets/dolly_data.json"
第三步: 在ft_datasets文件夹中添加dolly_dataset.py文件(请确保文件名dolly_dataset.py与上一步类名class dolly_dataset一致):
# Copyright (c) Meta Platforms, Inc. and affiliates.
# This software may be used and distributed according to the terms of the Llama 2 Community License Agreement.
# For dataset details visit: https://crfm.stanford.edu/2023/03/13/alpaca.html
import copy
import json
import os
import torch
from sentencepiece import SentencePieceProcessor
from torch.utils.data import Dataset
from typing import List
PROMPT_DICT = {
"prompt_input": (
"Below is an instruction that describes a task, paired with an input that provides further context. "
"Write a response that appropriately completes the request.\n\n"
"### Instruction:\n{instruction}\n\n### Input:\n{context}\n\n### Response:"
),
"prompt_no_input": (
"Below is an instruction that describes a task. "
"Write a response that appropriately completes the request.\n\n"
"### Instruction:\n{instruction}\n\n### Response:"
),
}
class InstructionDataset(Dataset):
def __init__(self, dataset_config, tokenizer, partition="train", max_words=30):
# 把json文件读取进来放入self.ann字典
# 注意dolly_data.json有 instruction, context, response 三个字段
self.ann = json.load(open(dataset_config.data_path))
if partition == "train":
self.ann = self.ann
else:
self.ann = self.ann[:200]
self.max_words = max_words
self.tokenizer = tokenizer
def __len__(self):
return len(self.ann)
def __getitem__(self, index):
ann = self.ann[index] # 取json数据列表中的一条字典数据
if ann.get("context", "") == "": # 取context字典,如果为空,则使用PROMPT_DICT中的prompt_no_input格式构造数据
prompt = PROMPT_DICT["prompt_no_input"].format_map(ann) # 把json字典数据中的每个字段填入prompt_no_input模板
# 注意prompt_no_input中只有一个 {instruction} slot, 因此就是把ann数据中的instruction 文本复制到prompt_no_input中替换{instruction} slot
else: # 如果context不为空,使用PROMPT_DICT中的prompt_input格式构造数据
prompt = PROMPT_DICT["prompt_input"].format_map(ann)
example = prompt + ann["response"] # 把ann中的response文本添加到prompt文本最后面
prompt = torch.tensor(
self.tokenizer.encode(prompt), dtype=torch.int64
)
example = self.tokenizer.encode(example)
example.append(self.tokenizer.eos_token_id)
example = torch.tensor(
example, dtype=torch.int64
)
padding = self.max_words - example.shape[0]
if padding > 0:
example = torch.cat((example, torch.zeros(padding, dtype=torch.int64) - 1))
elif padding < 0:
example = example[: self.max_words]
labels = copy.deepcopy(example)
labels[: len(prompt)] = -1
example_mask = example.ge(0)
label_mask = labels.ge(0)
example[~example_mask] = 0
labels[~label_mask] = 0
example_mask = example_mask.float()
label_mask = label_mask.float()
return {
"input_ids": example,
"labels": labels,
"attention_mask":example_mask,
}
第四步: 在ft_datasets/__init__.py文件中添加dolly_dataset.py的导入代码。
# Copyright (c) Meta Platforms, Inc. and affiliates.
# This software may be used and distributed according to the terms of the Llama 2 Community License Agreement.
from .grammar_dataset import get_dataset as get_grammar_dataset
from .alpaca_dataset import InstructionDataset as get_alpaca_dataset
from .samsum_dataset import get_preprocessed_samsum as get_samsum_dataset
from .dolly_dataset import InstructionDataset as get_dolly_dataset # 我们添加的代码
第五步: 在utils/dataset_utils.py文件中配置dolly_dataset。
# Copyright (c) Meta Platforms, Inc. and affiliates.
# This software may be used and distributed according to the terms of the Llama 2 Community License Agreement.
import torch
from functools import partial
from ft_datasets import (
get_grammar_dataset,
get_alpaca_dataset,
get_samsum_dataset,
get_dolly_dataset, # 我们添加的代码
)
from typing import Optional
DATASET_PREPROC = {
"alpaca_dataset": partial(get_alpaca_dataset, max_words=224),
"grammar_dataset": get_grammar_dataset,
"samsum_dataset": get_samsum_dataset,
"dolly_dataset": partial(get_dolly_dataset, max_words=2048), # 我们添加的代码
}
def get_preprocessed_dataset(
tokenizer, dataset_config, split: str = "train"
) -> torch.utils.data.Dataset:
if not dataset_config.dataset in DATASET_PREPROC:
raise NotImplementedError(f"{dataset_config.dataset} is not (yet) implemented")
def get_split():
return (
dataset_config.train_split
if split == "train"
else dataset_config.test_split
)
return DATASET_PREPROC[dataset_config.dataset](
dataset_config,
tokenizer,
get_split(),
)
完成如上步骤后可在运行微调代码时使用--dataset dolly_dataset命令。如果你添加了一个新的custom_dataset,你想在这个数据集上进行微调,那么就是--dataset custom_dataset。
(3) 执行微调,训练模型
(3.1) SSH命令行服务器10.102.53.103上
前提条件: 按照(1.1)登陆服务器后激活虚拟环境。
该机器上只有一个A6000 GPU, 只能执行单节点单GPU训练。
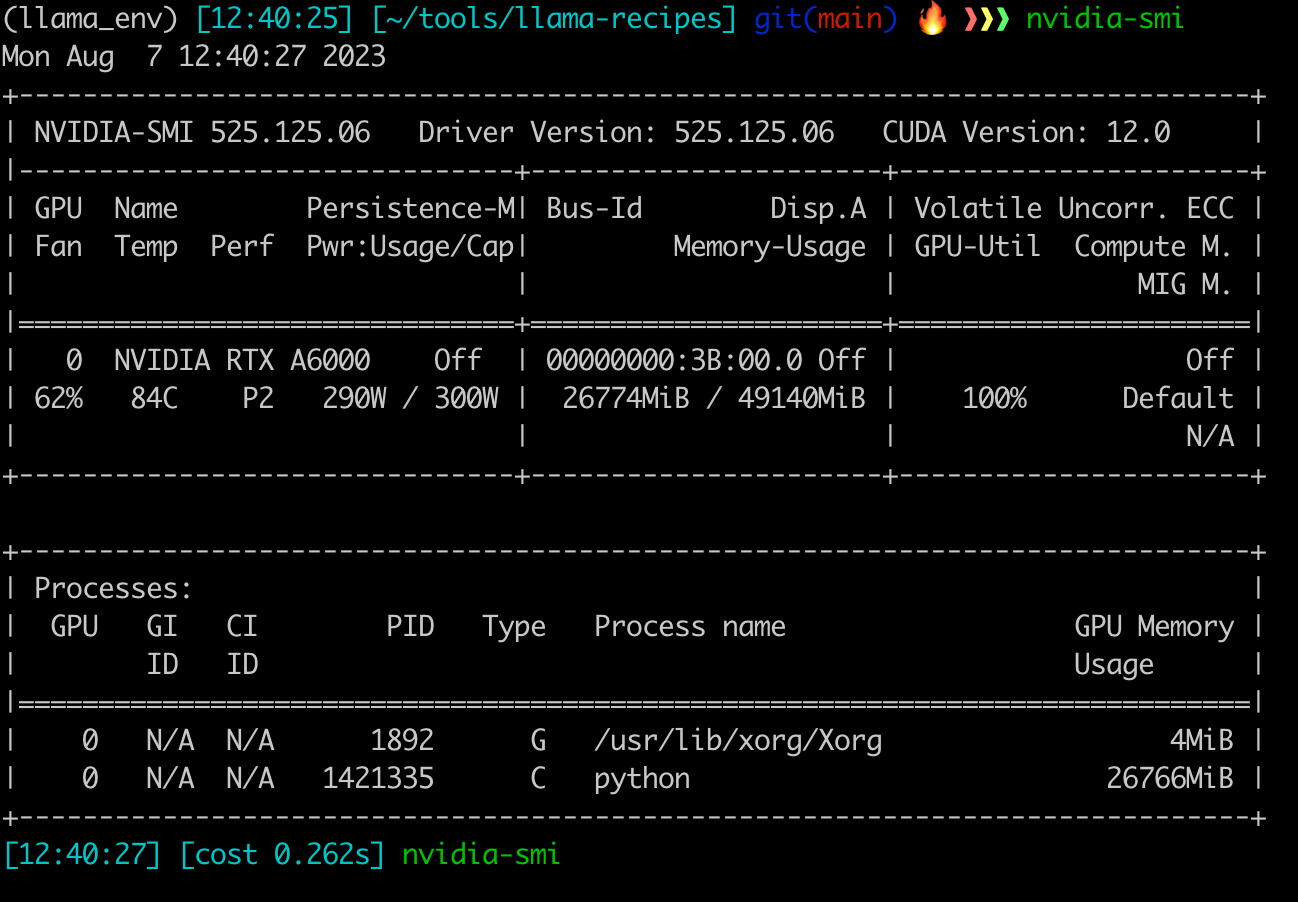
nvidia-smi 103
还是以dolly_dataset为例,在dolly_dataset上微调模型可用如下命令:
#if running on multi-gpu machine
export CUDA_VISIBLE_DEVICES=0
nohup python llama_finetuning.py --dataset dolly_dataset --use_peft --peft_method lora --quantization --use_fp16 --num_epochs 2 --model_name /home/dell/.cache/huggingface/hub/models--meta-llama--Llama-2-7b-hf/snapshots/3f025b66e4b78e01b4923d510818c8fe735f6f54 --output_dir /data/reasearch-tools/llama-2-7b-hf-dolly > dolly.log&
第一行export CUDA_VISIBLE_DEVICES=0设置训练模型所使用的GPU
第二行nohup xxx > dolly.log& 是只让xxx程序在后台运行,并且把输出记录到dolly.log文件中。
第二行python llama_finetuning.py --dataset dolly_dataset --use_peft --peft_method lora --quantization --use_fp16 --num_epochs 1 --model_name /home/dell/.cache/huggingface/hub/models--meta-llama--Llama-2-7b-hf/snapshots/3f025b66e4b78e01b4923d510818c8fe735f6f54 --output_dir /data/reasearch-tools/llama-2-7b-hf-dolly需要关注的参数有:
--dataset dolly_dataset使用的数据集是什么,--dataset参数的值dolly_dataset必须在utils/dataset_utils.py文件中配置过。--num_epochs 1微调几个epochs,一般可以用1个,2个或以上也许会出现过拟合。--model_name /home/dell/.cache/huggingface/hub/models--meta-llama--Llama-2-7b-hf/snapshots/3f025b66e4b78e01b4923d510818c8fe735f6f54加载的预训练模型,当前机器GPU显存不足,只能用7B。--output_dir /data/reasearch-tools/llama-2-7b-hf-dolly输出的peft模型位置,注意一定放在/data/reasearch-tools/XXXXX这个``/data/reasearch-tools/`文件夹下。
(3.2) HPC网页端服务器http://10.102.53.100/上
前提条件: 按照(1.2)登陆服务器后激活虚拟环境。
该机器上有2个V100 GPU, 只能执行单节点多GPU训练。
nvidia-smi 100
nohup torchrun --nnodes 1 --nproc_per_node 2 llama_finetuning.py --enable_fsdp --use_peft --peft_method lora --dataset alpaca_dataset --num_epochs 1 --model_name ./pre-models/7B --pure_bf16 --output_dir ./peft-models/alpaca-lora-7b > alpaca.log&
需要关注的参数有:
--dataset alpaca_dataset,alpaca_dataset替换成自定义数据集的名字,比如dolly_dataset--output_dir ./peft-models/alpaca-lora-7b,./peft-models/lora-7b替换成自定义数据集加模型名,比如./peft-models/dolly-lora-7b
执行微调命令后,请确认模型训练正常运行。用 llama training messagecat xxxx.log命令查看一下日志文件,出现如下结果,则证明训练已经开始。

(4) 使用微调模型进行推理(TODO)
待补充……